Download Mincraft - http://ru-m.org/programmy-minecraft/3776-piratskiy-launcher-minecraft-tlauncher.html
http://ru-m.org/gaydy-minecraft/15319-kak-obnovit-drayvera-videokarty-dlya-minecraft-tlauncher.html
Saturday, April 30, 2016
Friday, April 29, 2016
COLLECTIONS - mutable List vs unmodifiable view of List
When you use Collections.unmodifiableList(list) it will return unmodifiable view of that list, it means you will get an UnsupportedOperationException on add() over that view etc.
But in the same time the list itself remains to be mutable in case it is modified in proper way e.g. by the programm API.
But in the same time the list itself remains to be mutable in case it is modified in proper way e.g. by the programm API.

GRALDE - add custom external *.jar to module dependencies
1. An example is map-visualiser project from github
2. Clone that project and make gradlew build for it
3. It will build its *.jar inside of /build/libs
4. Create libs dir inside your module
5. Copy/past that *.jar into your module libs dir
6. Add these LOCs below into module's build.gradle and build the project:repositories {
mavenCentral()
flatDir {
dirs 'libs'
}
}
dependencies {
compile name: 'map-visualiser-1.0'
testCompile group: 'junit', name: 'junit', version: '4.11'
}
Thursday, April 28, 2016
JAVA CONCURRENCY - my notes for Applying Concurrency and Multi-threading to Common Java Patterns
Applying Concurrency and Multi-threading to Common Java Patterns on Pluralsight.com
Author blog (Jose Paumard): http://blog.paumard.org/en/

Author blog (Jose Paumard): http://blog.paumard.org/en/
GOLDEN RULE IN CONCURRENT PROGRAMMING
Never expose to outside the lock object
you use to synchronize your code!!!

Wednesday, April 27, 2016
SCALA - Scala for Java developers notes
Resources:
This course on Pluralsight
http://scalaforfunandprofit.com/why-use-fsharp/
http://docs.scala-lang.org/style/
History
Started in 2003 as research project in Switzerland.
Research was headed by Martin Odersky - an author of Java Generics and Java compiler.

Scala was adapted by:

Scala is for the future Software Development and there is non too much experienced devs
http://insights.dice.com/2014/04/04/employers-cant-find-enough-scala-talent/
Pure functions
Is associated with objects and work without a side-effects (or mutation).
Define fixed variable - vow.
Higher order functions
Functions are "first citizens" in Scala. This why functions could:
This course on Pluralsight
http://scalaforfunandprofit.com/why-use-fsharp/
http://docs.scala-lang.org/style/
History
Started in 2003 as research project in Switzerland.
Research was headed by Martin Odersky - an author of Java Generics and Java compiler.


Scala is for the future Software Development and there is non too much experienced devs
http://insights.dice.com/2014/04/04/employers-cant-find-enough-scala-talent/
Pure functions
Is associated with objects and work without a side-effects (or mutation).
Define fixed variable - vow.
Higher order functions
Functions are "first citizens" in Scala. This why functions could:
- receive other functions in its parameters
- return functions
- to be stored for later execution
Tuesday, April 26, 2016
ANGULAR 2 - first look by John Papa
Property Binding


HTTP Services: Observable and Subscribe


Async Pipe: How Components code is simplified by it


Async Pipe can return Promise (so you can use ".then(f())") instead of Observable if you want


Routes: Declaring Routing Directives in @Component

Routes: Use Routing in HTML

The main A2 imports
import { Component } from 'angular2/core';
import { HTTP_PROVIDERS } from 'angular2/http';
import { RouteConfig, ROUTER_DIRECTIVES, ROUTER_PROVIDERS } from 'angular2/router';
import 'rxjs/Rx'; // load the full rxjs
Use Routing for Menu with its Content

AGILE - comparison Agile with other mthodologies like Waterfall etc
SUMMARY

Waterfall

Waterfall V-Model













Waterfall

Waterfall V-Model

Agile comparison

Agile Manifesto

12 principles behind the Agile Manifesto can be split into 3 groups:
- Regular delivery of software
- Team communication
- Excellence in design
Our highest priority is to satisfy the customer through early and continues delivery of valuable software.
Delivery working software frequently (couple weeks - couple months), a preference is shorter timescale.
Working software is the primary measure of progress. (In Scrum the feature is DONE means it is potentially shippable).
=====
Business people and developers must work together daily. They should be available for each other.
Face-to-Face communication is a better way to convey the information.
Self-organised team gives the most valuable product.
Build projects around motivated individuals.
RETROSPECTIVE: At regular intervals, the team reflects on how to become more effective
======
Continuous attention to technical excellence and good design enhances agility.
Simplicity is essential. Do just what you need now, not in sometime in the future.
Welcome changing requirements, event in late development.
===== METHODOLOGIES OF AGILE =======
Scrum is a lightweight management framework.
Extreme programming is a disciplined approach at delivering high quality software quickly and continuously (delivery of 1-3 weeks).
Crystal methodology.
Dynamic Systems Development Method.
Feature Driven Design. (FDD) (time-lapse 2 weeks)
Kanban.
Extreme Programming

Rules: planning, managing, design, coding, testing
====
4 Activities: coding, testing, listening (customers & users), designing
5 Values: communication (f-2-f), simplicity (solving today's problem today), feedback, courage (realise issues and fix it), respect
3 Principles: feedback, assuming simplicity, embracing change
12 Practices /4 groups: fine-scale feedback (pair programming), continuous process, shared understanding, programmer welfare
29 Rules /5 groups: planning, managing, designing, coding
SCRUM

Split in 3 areas:
Roles: product owner (ussualy analist that communicate w/customer), scrum master (servant leader that fullfill the needs of the team), scrum team (5-9 people)
Ceremonies: sprint planning meeting, sprint review, sprint retrospective, daily scrum
Artifacts: product backlog, sprint backlog, burndown chart







======= DIFFERENCE between SCRUM and EXTREME PROGRAMMING ====
Scrum - has sprints from 2 weeks up to 1 month
XP - has iterations from 2 weeks
Scrum - teams do not allow changes into their sprints
XP - amenable to change within their iterations
Scrum - the team determine the sequence in which they will develop backlog items
XP - teams work in a strict priority order
Scrum - doesn't prescribe any engineering pactices
XP - prescribes many engineering practices like TDD, Pair Programming, Continuous Integration
In practice: team take Scrum, but adds some engineering practices from XP like TDD, Continuous integration, Code Review (instead of Pair Programming)
Monday, April 25, 2016
Saturday, April 23, 2016
Friday, April 22, 2016
CACHE - distributed cache
http://www.codeproject.com/Articles/21508/Distributed-Caching-Using-a-Hash-Algorithm

In computing, a distributed cache is an extension of the traditional concept of cache used in a single locale. A distributed cache may span multiple servers so that it can grow in size and in transactional capacity. It is mainly used to store application data residing in database and web session data.
Hashing algorithm that can be used in distributed caching of data in web farms or implementing a distributed hash table (DHT).
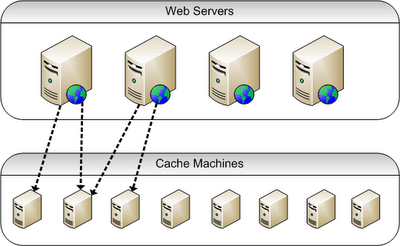
We have a layer of web servers that handle the requests and a pool of machines that are used for caching. Each web server should be able to access any of the cache machines. The tricky aspect here is that when we cache some data as a result of a request to a particular web server, we should be able to retrieve that data from any of the other web servers.
Here is what we can do. We want to cache key value pairs and then at a later stage get hold of a cached value by providing the corresponding key. The code below takes a key and produces a hash bit array using SHA1. Then after some transformations we derive an integer number. A given key always produces the same number. In addition, all numbers are uniformly distributed which allows us to "page" them and assign them to a given number of cache machines or "buckets".
In computing, a distributed cache is an extension of the traditional concept of cache used in a single locale. A distributed cache may span multiple servers so that it can grow in size and in transactional capacity. It is mainly used to store application data residing in database and web session data.
Hashing algorithm that can be used in distributed caching of data in web farms or implementing a distributed hash table (DHT).
We have a layer of web servers that handle the requests and a pool of machines that are used for caching. Each web server should be able to access any of the cache machines. The tricky aspect here is that when we cache some data as a result of a request to a particular web server, we should be able to retrieve that data from any of the other web servers.
Here is what we can do. We want to cache key value pairs and then at a later stage get hold of a cached value by providing the corresponding key. The code below takes a key and produces a hash bit array using SHA1. Then after some transformations we derive an integer number. A given key always produces the same number. In addition, all numbers are uniformly distributed which allows us to "page" them and assign them to a given number of cache machines or "buckets".
Thursday, April 21, 2016
ALGORYTHMS - animated and video examples
http://www.sorting-algorithms.com/
https://www.youtube.com/embed/vxENKlcs2Tw
https://www.youtube.com/embed/vxENKlcs2Tw
Tuesday, April 19, 2016
Wednesday, April 13, 2016
JAVASCRIPT - visualization of Bitcoins transactions by JS frameworks
Post in Twitter about the matter: https://twitter.com/pluralsight/status/719978158963978240
Example of JS visualization of Bitcoin transactions: http://bitbonkers.com/
JS framework Three JS: http://threejs.org/
JS framework Oimo JS: http://lo-th.github.io/Oimo.js/
Live stream of Bitcoins transactions: https://blockchain.info/
Example of JS visualization of Bitcoin transactions: http://bitbonkers.com/
JS framework Three JS: http://threejs.org/
JS framework Oimo JS: http://lo-th.github.io/Oimo.js/
Live stream of Bitcoins transactions: https://blockchain.info/
Tuesday, April 12, 2016

Monday, April 11, 2016
TCP - 3 Way handshake SYN, SYN-ACK, ACK
http://www.inetdaemon.com/tutorials/internet/tcp/3-way_handshake.shtml

| EVENT | DIAGRAM |
Host A sends a TCP SYNchronize packet to Host B
Host B receives A's SYN
Host B sends a SYNchronize-ACKnowledgement
Host A receives B's SYN-ACK
Host A sends ACKnowledge
Host B receives ACK.
TCP socket connection is ESTABLISHED.
|  TCP Three Way Handshake (SYN,SYN-ACK,ACK) |
Sunday, April 10, 2016
ORACLE - fundamentals of Relational model and Oracle RDBMS
Oracle officially Oracle is called an Object-relational database.
RDBMS - Relational Database Management System
Oracle v1 - 1978 and never released
Oracle 8i - 1999 i stands for Internet (possibility to query DB online)
Oracle 10g - 2000 g stands for Grid Computing
Oracle 12c - 2014 c stands for Cloud
Grid infrastructure refErs to deploying of a Massively Parallel infrastructure with storage fabric for building a shared storage that consist from pluggable hard drives (HDs) that can be extended by adding more HDs.
Automatic Storage Management (ASM) is Oracle software feature for Grid infrastructure.
Real Application Cluster (RAC) is an Oracle technology
In Oracle Grid infrastructure you can cluster your application servers, storage (ASM) and database (RAC) - and end-to-end high availability solution.
======== TWO MEMORY STRUCTURES IN ORACLE DB ==========================
SGA - System Global Area (main collection of shared data caches, for Instances - shareable memory)
PGA - Process Global Area (for each session of user, keeps its preferences, logs, SQL queries etc)
=========== ORACLE INSTANCE DOCS =================================
http://docs.oracle.com/database/121/CNCPT/startup.htm#CNCPT005
=========== PL/SQL anti-pattern - use of DML inside LOOP ==========
==================== ADVANTAGES OF ORACLE =======================
There are numerous features, that are quite unique. If I had to pick the ones that I consider killer, these would be:
Theory:
First description of Relational model in 1970 by EF "Ted" Codd: http://is.gd/eBKRHY
or http://bio.informatics.iupui.edu/beyond/misc/codd%20relational%20model%201970.pdf
Columns of the table could be called Domains
Rows of the table can be called Tuples
Table can be called Relation (that has n-tuples in it)
Active Domain of instant - the set of values represented at that instant.
Primary key - one domain of a given relation has values which uniquely identify each element (n-tuple) of that relation.
Primary key is nonredundant if it uniquely identify each element.
Relation can have more than one nonredundant primary keys, but only one of them should be selected and called THE primary key of this relation.
Foreign Key - domain of relation R is a Foreign Key if it is not the primary key of R but its elements are values of the primary key of some relation S.
Simple domains - domains whose elements are atomic (nondecomposable) values.
Normalization - is elimination of nonsimple domains.
Model - the relational view of data
Theory of Relations: https://en.wikipedia.org/wiki/Finitary_relation
Einstein's General relativity:
https://en.wikipedia.org/wiki/General_relativity
==================================
RDBMS - Relational Database Management System
Oracle v1 - 1978 and never released
Oracle 8i - 1999 i stands for Internet (possibility to query DB online)
Oracle 10g - 2000 g stands for Grid Computing
Oracle 12c - 2014 c stands for Cloud
Grid infrastructure refErs to deploying of a Massively Parallel infrastructure with storage fabric for building a shared storage that consist from pluggable hard drives (HDs) that can be extended by adding more HDs.
Automatic Storage Management (ASM) is Oracle software feature for Grid infrastructure.
Real Application Cluster (RAC) is an Oracle technology
In Oracle Grid infrastructure you can cluster your application servers, storage (ASM) and database (RAC) - and end-to-end high availability solution.
======== TWO MEMORY STRUCTURES IN ORACLE DB ==========================
SGA - System Global Area (main collection of shared data caches, for Instances - shareable memory)
PGA - Process Global Area (for each session of user, keeps its preferences, logs, SQL queries etc)
=========== ORACLE INSTANCE DOCS =================================
http://docs.oracle.com/database/121/CNCPT/startup.htm#CNCPT005
=========== PL/SQL anti-pattern - use of DML inside LOOP ==========
Never manipulate tables data (by DML) from inside PROCEDURE LOOPS.
Data Manipulation Language (DML) is a vocabulary used to retrieve and work with data in SQL Server 2016. Use these statements to add, modify, query, or remove data from a SQL Server database.https://apexapps.oracle.com/pls/apex/f?p=44785:141:0::NO::P141_PAGE_ID,P141_SECTION_ID:168,1208==================== ADVANTAGES OF ORACLE =======================
There are numerous features, that are quite unique. If I had to pick the ones that I consider killer, these would be:
- ASM (Automatic Storage Management) makes the storage management so much easier and smoother.
- RAC (Real Application Clusters) - this is something you will not find anywhere else and was the reason we went Oracle in the first place. Sure, there are replication or some sort of clustering solutions for other databases, but nothing comes close to RAC.
- Realiability - this is a good thing in a database :) Oracle just won't eat your data. I have seen MySQL databases corrupted beyond repair, I have seen MSSQL database fall to pieces. I have yet to see Oracle do something, that is not easily recoverable (with the right backup and HA strategy of course).
- Management - the Enterprise manager is awesome tool
- Monitoring and diagnostics - Oracle measures and reports everything and I mean everything. It is not always simple to extract, but all the information you need to tune or debug the database or applications using the database is available.
Theory:
First description of Relational model in 1970 by EF "Ted" Codd: http://is.gd/eBKRHY
or http://bio.informatics.iupui.edu/beyond/misc/codd%20relational%20model%201970.pdf
Columns of the table could be called Domains
Rows of the table can be called Tuples
Table can be called Relation (that has n-tuples in it)
Active Domain of instant - the set of values represented at that instant.
Primary key - one domain of a given relation has values which uniquely identify each element (n-tuple) of that relation.
Primary key is nonredundant if it uniquely identify each element.
Relation can have more than one nonredundant primary keys, but only one of them should be selected and called THE primary key of this relation.
Foreign Key - domain of relation R is a Foreign Key if it is not the primary key of R but its elements are values of the primary key of some relation S.
Simple domains - domains whose elements are atomic (nondecomposable) values.
Normalization - is elimination of nonsimple domains.
Model - the relational view of data
Theory of Relations: https://en.wikipedia.org/wiki/Finitary_relation
Mathematically, then, a relation is simply an "ordered set". (k-ary, e.g ternary = 3-ary)
When two objects, qualities, classes, or attributes, viewed together by the mind, are seen under some connexion, that connexion is called a relation.Newton's law of universal gravitation: https://en.wikipedia.org/wiki/Newton%27s_law_of_universal_gravitation
— Augustus De Morgan
Einstein's General relativity:
https://en.wikipedia.org/wiki/General_relativity
==================================
Friday, April 8, 2016
BIG DATA - MapReduce vs Massively Parallel Processing (MPP)
Comparison between MapReduce and MPP (Massively Parallel Processing)


Thursday, April 7, 2016
ALGORITHM - DFS Depth-first Search
Depth-first search (DFS) is an algorithm for traversing or searching tree or graph data structures. One starts at the root (selecting some arbitrary node as the root in the case of a graph) and explores as far as possible along each branch before backtracking.
https://en.wikipedia.org/wiki/Depth-first_search
https://en.wikipedia.org/wiki/Depth-first_search
JAVASCRIPT - difference between call and apply functions
CALL
https://developer.mozilla.org/ru/docs/Web/JavaScript/Reference/Global_Objects/Function/call
APPLY
https://developer.mozilla.org/ru/docs/Web/JavaScript/Reference/Global_Objects/Function/apply
Its functions almost similar.
Its fundamental difference is that call() receive in its parameters a LIST of arguments, but apply() - single array of arguments.
Примечание: хотя синтаксис этой функции практически полностью идентичен функции
https://developer.mozilla.org/ru/docs/Web/JavaScript/Reference/Global_Objects/Function/call
APPLY
https://developer.mozilla.org/ru/docs/Web/JavaScript/Reference/Global_Objects/Function/apply
Its functions almost similar.
Its fundamental difference is that call() receive in its parameters a LIST of arguments, but apply() - single array of arguments.
Примечание: хотя синтаксис этой функции практически полностью идентичен функции
apply(), фундаментальное различие между ними заключается в том, что функция call() принимает список аргументов, в то время, как функция apply() - одиночный массив аргументов.
JAVASCRIPT - the use of bind method of Function.prototype.bind()
https://developer.mozilla.org/ru/docs/Web/JavaScript/Reference/Global_Objects/Function/bind
Method bind() will bind the scope of the object's (passed as parameter) this to the function on which it was called.
Method bind() will bind the scope of the object's (passed as parameter) this to the function on which it was called.
this.x = 9;
var module = {
x: 81,
getX: function() { return this.x; }
};
module.getX(); // 81
var getX = module.getX;
getX(); // 9, поскольку в этом случае this ссылается на глобальный объект
// создаём новую функцию с this, привязанным к module
var boundGetX = getX.bind(module);
boundGetX(); // 81function list() {
return Array.prototype.slice.call(arguments);
}
var list1 = list(1, 2, 3); // [1, 2, 3]
// Создаём функцию с предустановленным ведущим аргументом
var leadingThirtysevenList = list.bind(undefined, 37);
var list2 = leadingThirtysevenList(); // [37]
var list3 = leadingThirtysevenList(1, 2, 3); // [37, 1, 2, 3]Wednesday, April 6, 2016
IMPOSTOR SYNDROME - when an experienced programmer feel like a perpetual beginner
I've been programming for 6 years and I feel like I'm a perpetual beginner. Do many other programmers feel this way?
Answers from different programmers:
Yes, it's called Impostor Syndrome. If you want to see an army of beginners, walk into a high tech company full of experienced programmers.
Well, that's pretty the same thing for 99% of devs.
When you start questioning yourself, that's very good - means that from now on, the real programming starts.
We grow in cycles and you need to invest most patience when you doubt yourself the most! and just go to that online course or book or repl and just to a tiny little program.
Yes, it's called Impostor Syndrome. If you want to see an army of beginners, walk into a high tech company full of experienced programmers.
Well, that's pretty the same thing for 99% of devs.
When you start questioning yourself, that's very good - means that from now on, the real programming starts.
We grow in cycles and you need to invest most patience when you doubt yourself the most! and just go to that online course or book or repl and just to a tiny little program.
MapReduce. What is it?
MapReduce is compound from two main steps:
Map step (input files)
Map step is the process of going through the unformatted data and generating a series of key-value pairs.
Shuffle intermediate step (processing of the data of input files)
All of the values for a given key are collated into separated piles (common keys go to one folder).
Reduce step (output files)
Producer Node will count tally for each key (from all data values of that key is a folder)

Map step (input files)
Map step is the process of going through the unformatted data and generating a series of key-value pairs.
Shuffle intermediate step (processing of the data of input files)
All of the values for a given key are collated into separated piles (common keys go to one folder).
Reduce step (output files)
Producer Node will count tally for each key (from all data values of that key is a folder)

HADOOP
Hadoop = MapReduce + HDFS
It is an Apache project combining:
MapReduce engine with Hadoop Distributed File System (HDFS)
HDFS allows many local disks of each Node operate in a Hadoop Cluster as a single pool of storage.
Files are replicated across nodes (by default 1 original has 2 copies, 3 in total)
Hadoop stack (from bottom to top)


It is an Apache project combining:
MapReduce engine with Hadoop Distributed File System (HDFS)
HDFS allows many local disks of each Node operate in a Hadoop Cluster as a single pool of storage.
Files are replicated across nodes (by default 1 original has 2 copies, 3 in total)
Hadoop stack (from bottom to top)
- MapReduce + HDFS
- Database: HBase (NoSQL Database). HBase tables are HDFS files. Optionally HBase tables can be used as an input for MapReduce jobs or MapReduce job's output can create a new HBase table.
- Query: HiveQL (SQL abstraction layer over MapReduce) + Pig Latin (its commands corresponds to a different SQL commands: used for querying and stepwise data transformation as an ETL tool)
- RDBMS Import/Export: Sqoop (Additional component to Hive and Pig, moves data between Hadoop and any RDBMS)
- Machine Learning / Data Mining: Mahout
- Log file integration: Flume

EMR (Elastic MapReduce) is a Hadoop distro from AWS
It has in common: MapReduce and HDFS + Database + Hive and Pig.
It adds MPP \ Column Store: Impala (Cloudera)
Hive and Pig is an abstraction layer over MapReduce. Hive is a batch system.
Impala is an abstraction layer over HDFS. Impala is an interactive query engine.

Tuesday, April 5, 2016
NoSQL categories and DynamoDB example
NoSQL has 4 categories:
Key-Value stores (AWS DynamoDB)
Document stores (MongoDB)
Graph stores (Nodes keep the data)
Wide Column / Column Family stores





Key-Value stores (AWS DynamoDB)
Document stores (MongoDB)
Graph stores (Nodes keep the data)
Wide Column / Column Family stores

In Key-Value store e.g. DynamoDB tables have rows, rows have key and value

Querying in Key-Value store



CAP theorem - Consistency, Availability, Partition Tolerance
CAP stands for:
Consistency, Availability, Partition Tolerance
SQL
priorities Consistency first and then Partition Tolerance
NoSQL
priorities Partition Tolerance first and then Availability

Consistency, Availability, Partition Tolerance
SQL
priorities Consistency first and then Partition Tolerance
NoSQL
priorities Partition Tolerance first and then Availability

AWS - Big Data stack components components overview
AWS Big Data stack components overview
Cloud-based, Massively Parallel Processing (MPP), column store data warehouse.
Uses common relational, SQL technology.
Integrated with S3 and DynamoDB
DynamoDB
Based on Dynamo, Amazon's internal, seminal Key-Value store
Accommodates unstructured data - no schema needs to be declared
Replaced Amazon SimpleDB
Data Pipline (ETL tool - Extract Transform Load)
- Elastic MapReduce (EMR)
- Redshift
- DynamoDB
- Data Pipline (ETL tool)
- Simple Storage Service (S3)
- Jaspersoft AWS
- Kinesis (streaming data)
Elastic MapReduce (MapReduce - processing algorythm)
Amazon implementation of Hadoop
Hadoop-on-Demand
Integrated with S3 (Simple Storage Service)
Amazon distro or MapR
MapR - Unlike other Hadoop distributions that require separate clusters for multiple applications, the MapR Platform is built to process both distributed files, database tables, and event streams in one unified layer – an engineering feat in its own right. This enables organizations to support both operational (e.g., HBase) and analytic apps (e.g., Apache Drill, Hive, or Impala) on one cluster, significantly reducing costs as you grow your big data deployment. https://www.mapr.com/why-hadoop/why-maprRedshift
Cloud-based, Massively Parallel Processing (MPP), column store data warehouse.
Uses common relational, SQL technology.
Integrated with S3 and DynamoDB
DynamoDB
Based on Dynamo, Amazon's internal, seminal Key-Value store
Accommodates unstructured data - no schema needs to be declared
Replaced Amazon SimpleDB
Data Pipline (ETL tool - Extract Transform Load)
A workflow system for shaping data and moving data from table to table, DB to DB +=>
Serves as an Integration tool for AWS Big Data stack components (moves components)
Build pipelines graphically (WEB) or programmatically (scripts)
Works on a scheduled, batch bases
Integrates with RDS/MySQL (Relational Database Service from Amazon - SQL distributed solution)
Important Acronyms
AWS Amazon Web Services
EC2 Elastic Compute Cloud
AMI Amazon Machine Image
S3 Simple Storage Service
EMR Elastic MapReduce
VPC Virtual Private Cloud
IAM Identity and Access Management
SSH Secure Socket Shell
Getting Set Up with AWS
Create an account
Create a Key pair
Create an S3 bucket
Install SSH client
Install S3 client
Install SQL Workbench, drivers
Subscribe to:
Comments (Atom)